| 记录一次 mysql 百万级数据量使用group by 统计的优化 | 您所在的位置:网站首页 › mysql 千万级数据增加字段 › 记录一次 mysql 百万级数据量使用group by 统计的优化 |
记录一次 mysql 百万级数据量使用group by 统计的优化
|
一份二次开发的项目一张消费表中存储啦400万+ 的数据,现在要求 按照消费人的id 统计出每个人的消费总金额,因为是二次开发的项目之前不知道表中到底有多少数据 直接就按照一般的sql ,发现查询速度巨慢,执行一次24s+,刚开始以为是客户数据库问题,没想到数据迁移到本地后还是很慢,一查看数据库条数 400多万条,话不多说直接上sql 优化前的sql SELECT u_id, IFNULL(SUM(amount),0)amount ,SUM(IF(transaction_type=‘receipt’,amount,0))AS mount FROM ‘表名称’ GROUP BY u_id 直接执行 巨慢 查看返回结果 |
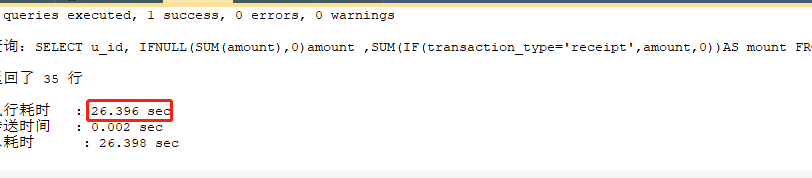 刚开始觉得是没有索引的问题 执行下列sql 查看 SHOW INDEX FROM ‘表名称’ 返回结果如下图
刚开始觉得是没有索引的问题 执行下列sql 查看 SHOW INDEX FROM ‘表名称’ 返回结果如下图  可以看到是有索引的 既然有索引 就要想着怎么取优化这段sql 也是问下度娘之后 使用FORCE INDEX()强制指定索引 抱着试一试的态度执行一次 优化后的sql SELECT u_id, IFNULL(SUM(amount),0)amount ,SUM(IF(transaction_type=‘receipt’,amount,0))AS mount FROM ‘表名称’ FORCE INDEX(索引名称) GROUP BY u_id 执行结果如下
可以看到是有索引的 既然有索引 就要想着怎么取优化这段sql 也是问下度娘之后 使用FORCE INDEX()强制指定索引 抱着试一试的态度执行一次 优化后的sql SELECT u_id, IFNULL(SUM(amount),0)amount ,SUM(IF(transaction_type=‘receipt’,amount,0))AS mount FROM ‘表名称’ FORCE INDEX(索引名称) GROUP BY u_id 执行结果如下  瞬间 由原来的26秒 降到差不多 4秒 ,先记录下来后面有更好的方法再更新
瞬间 由原来的26秒 降到差不多 4秒 ,先记录下来后面有更好的方法再更新【本文地址】
公司简介
联系我们